zkWasm Overview
1. Introduction to zkWasm
Note
This section provides a high-level overview of zkWasm. For more detailed information about zkWasm, please refer to the:
zkWasm represents a fundamental advancement in the field of trustless computation by combining WebAssembly with zero-knowledge proofs. The system implements a complete WebAssembly virtual machine within zkSNARK circuits, creating a bridge between traditional application development and blockchain technology. This approach allows developers to write programs in familiar languages while gaining the benefits of zero-knowledge proofs without requiring specialized cryptographic knowledge.
The core innovation of zkWasm lies in its approach to implementing zero-knowledge proofs. Rather than requiring developers to write programs in specialized circuit-friendly languages, zkWasm applies zero-knowledge proofs at the bytecode level of the virtual machine. This means that any program that can be compiled to WebAssembly can automatically benefit from zero-knowledge capabilities, making the technology accessible to a much broader range of developers and applications.
Traditional approaches to implementing zero-knowledge proofs often require developers to work with specialized languages and tools like Pinocchio, TinyRAM, or ZoKrates. This requirement creates a significant barrier to adoption, as developers must learn new programming paradigms and rewrite existing applications. zkWasm eliminates this barrier by operating at the WebAssembly level, allowing developers to work in languages they already know, such as C++, Rust, or AssemblyScript.
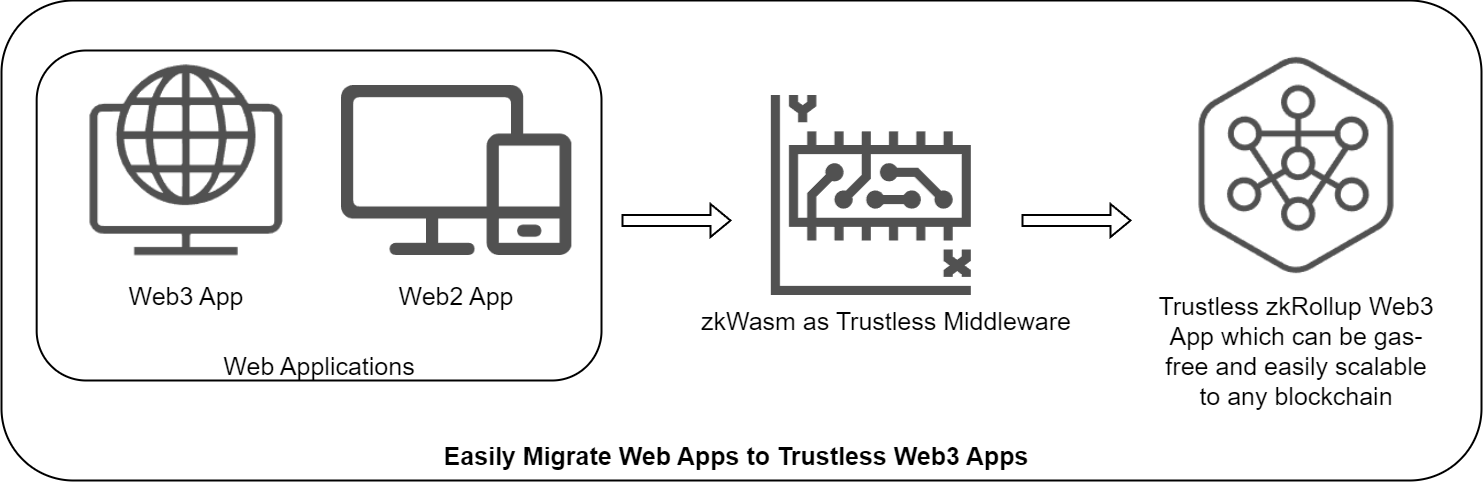
This accessibility extends beyond just the programming language choice. While traditional blockchain development requires extensive knowledge of specific blockchain protocols and smart contract languages, zkWasm further simplifies the blockchain integration process. By operating at the WebAssembly bytecode level, zkWasm automatically handles the generation of zero-knowledge proofs for any application logic like user operations and user interactions. These standardized proofs can be verified on any blockchain platform without requiring developers to write custom smart contracts or complex blockchain-specific protocols for application logic. This approach not only lowers the technical barriers for Web2 developers (as well as their users) entering the Web3 space, but also enables seamless cross-chain compatibility for their applications.
Info
Compared to the traditional Web3 applications which heavily rely on smart contracts and a specific blockchain system, zkWasm applications are more like Web2 applications, but with the trustless verification capabilities brought by zero-knowledge proofs, it can:
- Seamlessly integrate with existing Web2 or Web3 applications
- Allow developers to focus on business logic and frontend design, without the need to learn much about blockchain or zero-knowledge proofs
- Allow developers to easily switch between different blockchain platforms if needed
- Allow developers to easily scale or upgrade their applications
- Allow gasless interactions and operations (except for the proof verification, deposit and withdrawal which is required when manipulating the onchain assets) for application users
2. The State Machine Foundation
At its core, zkWasm operates as a state machine that processes WebAssembly bytecode while generating proofs of correct execution. The state machine takes as input a tuple consisting of several key components that together define the program and its execution environment. This tuple, represented as (I(C,H), E, IO), contains the WebAssembly executable image I (which includes both code C and initial memory state H), the entry point E, and the input/output firmware IO.
The state machine maintains an internal state that captures every aspect of program execution. This state, represented as a tuple (iaddr, F, M, G, Sp, I, IO), includes the current instruction address (iaddr), the call frame (F), memory state (M), global variables (G), and the execution stack (Sp). Each of these components plays a crucial role in program execution and proof generation.
Note
Understanding the state machine model is crucial for application development because:
- Design the state machine model before starting to write code will help a lot on development efficiency
- Your application's performance depends on minimizing state transitions
- Proper state handling is essential for correctness and security of your application
- Consider using tools to analyze your application's state transitions during development
State Representation and Execution Flow
The instruction address (iaddr) keeps track of the current position in the program, determining which instruction will be executed next. The call frame (F) manages function calls and their context, including a depth field that tracks the nesting level of function calls. This depth tracking is crucial for ensuring that all function calls properly return and maintaining the correct execution context.
Memory management in zkWasm is handled through the memory state (M), which represents the linear memory space available to the WebAssembly program. This memory can be read from and written to during program execution, with all operations being tracked and verified through the proof system. Global variables (G) provide a way to maintain state across function calls, while the stack (Sp) handles temporary values and computation results.
Program execution proceeds through a series of state transitions, with each transition function taking the current state and producing a new state based on the instruction being executed. These transitions form an execution trace that represents the complete history of program execution. The system ensures that each transition follows the WebAssembly specification and maintains the integrity of the program state.
Here's a core state structure in Rust:
struct State {
iaddr: InstructionAddress, // Current instruction address
F: CallFrame, // Call frame with depth
M: MemoryState, // Memory state
G: GlobalVariables, // Global variables
Sp: Stack, // Execution stack
I: WasmImage, // WASM executable image
IO: IOFirmware // Input/Output handling
}
State transitions and execution can be defined as:
type StateTransition = fn(State) -> State;
struct ExecutionTrace {
transitions: Vec<StateTransition>,
initial_state: State,
}
Let's examine a concrete example of how state transitions work in practice:
#[no_mangle]
pub extern "C" fn add(x: i32, y: i32) -> i32 {
x + y
}
This simple addition function generates several state transitions under the hood. Here's what happens:
let transitions = vec![
// Load first parameter
|s| State {
stack: s.stack.push(s.memory[s.iaddr + 1]),
iaddr: s.iaddr + 1,
..s
},
// Load second parameter
|s| State {
stack: s.stack.push(s.memory[s.iaddr + 1]),
iaddr: s.iaddr + 1,
..s
},
// Perform addition
|s| {
let (stack, y) = s.stack.pop();
let (stack, x) = stack.pop();
State {
stack: stack.push(x + y),
iaddr: s.iaddr + 1,
..s
}
}
];
Each transition represents a specific operation in the WebAssembly execution:
- The first transition loads parameter x from memory onto the stack
- The second transition loads parameter y
- The final transition pops both values, adds them, and pushes the result
The validity of an execution trace is verified as follows:
impl ExecutionTrace {
fn is_valid(&self) -> bool {
let mut current_state = self.initial_state;
// Verify each transition
for transition in &self.transitions {
current_state = transition(current_state);
// Verify transition follows WASM semantics
if !verify_semantics(current_state) {
return false;
}
}
// Verify final state
current_state.call_frame.depth == 0
}
}
3. Host (Builtin) Functions
Besides the WebAssembly instructions, zkWasm also provides a set of host functions that are not defined in the WebAssembly module itself but are provided by the environment in which the WebAssembly code is executed. These functions are crucial for WebAssembly modules to interact with the outside world, as WASM on its own is quite sandboxed and limited in what it can do directly.
Here are some key points about WASM host functions:
- Interaction with the Environment: WASM is designed to be a low-level, portable bytecode, which runs in a sandboxed environment. By itself, it doesn't have direct access to the system's resources like file systems, network, or the DOM in web browsers. Host functions serve as the bridge between the WASM code and these external resources.
- Provided by the Host Environment: The host environment (which could be a web browser, a server-side platform like Node.js, or any other system that supports running WebAssembly) defines and provides these host functions. For instance, in a web browser, the host functions might allow interactions with web APIs.
- Imported into WASM Modules: WASM modules import these host functions and use them as if they were part of the module. This import/export mechanism is part of the WASM design, allowing for modular code and separation of concerns.
- Custom Functionality: Host functions can be used to provide custom functionality to WASM modules that is not available in the standard WASM instruction set. This can include anything from accessing the file system to performing complex computations that are more efficiently done in the host language (like JavaScript in the case of web browsers).
In the zkWasm system, a wide range of pre-defined host functions are provided to make it easier to build complex applications. These host functions are divided into three main categories:
- I/O related host functions: These functions handle the input and output operations in zkWasm. They provide ways for reading both public and private inputs, keeping track of the current position in the input stream, and outputting results. The difference between public and private inputs is very important for zero-knowledge applications.
- Merkle tree related host functions: zkWasm includes a Merkle tree implementation for efficiently verifying large data structures. The Merkle tree host functions include setting the root, specifying leaf addresses, updating and retrieving values, and getting the root hash. These functions follow a specific set of rules to ensure consistency and verifiability.
- Cryptographic operation related host functions: zkWasm implements advanced cryptographic operations, particularly the Poseidon signature scheme, which works well with zero-knowledge proofs. The signature host functions use elliptic curve cryptography (through the BabyJubjub curve) and involve multi-scalar multiplication for verification. These functions provide a secure and efficient way to perform cryptographic operations within the zkWasm environment.
Note
When developing zkWasm applications:
- Use host functions for external interactions and cryptographic operations (like user operations and signature)
- Carefully manage the distinction between public and private inputs
- Leverage the Merkle tree functions for efficient data structure storage, retrieval, and verification, because in zkWasm, we implement Merkle tree as Database Service.
- Design your application architecture around these built-in capabilities rather than implementing custom solutions.
Input/Output System Implementation
The input/output system in zkWasm provides a mechanism for handling both public and private data. The system centers around the zkmain function, which serves as the entry point for all zkWasm applications. This function has the signature zkmain(void): (void), but can interact with the outside world through specialized host functions.
zkWasm distinguishes between public and private inputs through its input functions:
zkwasm_input(1)reads public inputs (instances) that will be visible in the proof.zkwasm_input(0)handles private inputs (witnesses) that should remain confidential.
This distinction is crucial for zero-knowledge applications, where some data must remain private while still proving computations were performed correctly.
The system maintains an internal cursor that tracks the current position in the input stream. When reading inputs, the system takes the value at the current cursor position, places it on top of the execution stack, and advances the cursor. This mechanism ensures orderly processing of inputs while maintaining the distinction between public and private data.
Merkle Tree Integration
An integral part of the I/O system is the Merkle tree implementation, which provides efficient verification of large data structures. zkWasm includes a built-in Merkle tree with a depth of 32 levels, supporting indices from 0 to 2^32-1.
The Merkle tree API provides the following functions:
extern "C" {
pub fn merkle_setroot(x: u64);
pub fn merkle_address(x: u64);
pub fn merkle_set(x: u64);
pub fn merkle_get() -> u64;
pub fn merkle_getroot() -> u64;
}
merkle_setroot: Sets the Merkle root to establish the context.merkle_address: Specifies the leaf address for the operation.merkle_set: Updates the value at the currently selected address.merkle_get: Retrieves the value at the currently selected address, along with a proof of inclusion.merkle_getroot: Returns the current root hash, which represents the entire state of the tree.
The Merkle tree operations follow a specific protocol to ensure consistency and verifiability. Here's an example:
#[no_mangle]
pub extern "C" fn merkle_tree_example() {
unsafe {
// Set up Merkle tree state
let root = [1u64, 2u64, 3u64, 4u64]; // Example root
// Set root for operations
for (i, &value) in root.iter().enumerate() {
merkle_setroot(value);
}
// Query leaf at index 0
merkle_address(0);
let value = merkle_get();
// Update leaf value
merkle_set(value + 1);
// Get new root after modification
let new_root = merkle_getroot();
zkwasm_output(new_root);
}
}
This example demonstrates a complete Merkle tree operation cycle:
- First, it initializes the tree with a known root
- Then it queries a specific leaf value
- Updates that value
- Finally retrieves the new root hash that reflects the change
The Merkle tree implementation supports efficient verification of data integrity. Here's an example of how verification works:
pub struct MerkleProof {
leaf_value: u64,
path: Vec<(u64, bool)>, // (hash, is_left)
root: u64,
}
impl MerkleProof {
pub fn verify(&self) -> bool {
let mut current_hash = self.leaf_value;
// Traverse the path from leaf to root
for &(sibling_hash, is_left) in &self.path {
current_hash = if is_left {
hash_pair(sibling_hash, current_hash)
} else {
hash_pair(current_hash, sibling_hash)
};
}
current_hash == self.root
}
}
This verification process ensures that a particular leaf value is indeed part of the Merkle tree with the given root. The path provides the necessary sibling hashes to reconstruct the root hash.
Signature Scheme
zkWasm implements the Poseidon signature scheme, which leverages elliptic curve cryptography through the BabyJubjub curve, providing efficient verification while maintaining security.
The signature consists of two components: - sig_r: A point on the BabyJubjub elliptic curve - sig_s: A scalar value used in the signature verification equation
struct JubjubSignature {
sig_r: BabyJubjubPoint,
sig_s: Scalar,
}
This verification process involves several steps:
- It performs a multi-scalar multiplication (msm) combining:
- The public key with the message hash
- The signature's R point with the constant ONE
- The negative of the base point with the s value
- The result should be the point (0, 1) if the signature is valid
impl JubjubSignature {
pub fn verify(&self, pk: &BabyJubjubPoint, msghash: &[u64; 4]) {
unsafe {
let r = BabyJubjubPoint::msm(&[
(pk, msghash),
(&self.sig_r, &ONE.0),
(&NEG_BASE, &self.sig_s),
]);
require(r.x.is_zero() && r.y == ONE);
}
}
}
Let's look at how this is used in practice:
#[no_mangle]
pub extern "C" fn verify_signature_example() {
unsafe {
// Read signature components from input
let sig_r_x = zkwasm_input(0);
let sig_r_y = zkwasm_input(0);
let sig_s = zkwasm_input(0);
// Read public key
let pk_x = zkwasm_input(1);
let pk_y = zkwasm_input(1);
// Read message hash
let msg_hash = [
zkwasm_input(1),
zkwasm_input(1),
zkwasm_input(1),
zkwasm_input(1),
];
// Construct signature object
let signature = JubjubSignature {
sig_r: BabyJubjubPoint::new(sig_r_x, sig_r_y),
sig_s: Scalar::new(sig_s),
};
// Verify signature
let pk = BabyJubjubPoint::new(pk_x, pk_y);
signature.verify(&pk, &msg_hash);
// Output verification result
zkwasm_output(1); // Success if we reach here
}
}
4. Proof Generation and Verification
The proof generation system in zkWasm handles the complexity of real-world applications through a segmentation approach. This is necessary because execution traces can contain millions of instructions, far exceeding what can be proved in a single circuit. The system breaks down long execution traces into manageable segments, each with its own proof, which are then combined into a complete verification of the entire execution.
Note
To optimize proof generation in your applications:
- Design with proof segmentation in mind
- Batch related operations to minimize segment boundaries
- Implement proper error handling that doesn't leak private information
- Consider the trade-offs between segment size and proof generation time
Each execution segment maintains its own starting state, sequence of instructions, ending state, and proof of correct execution:
struct ExecutionSegment {
start_state: State,
instructions: Vec<Instruction>,
end_state: State,
proof: SegmentProof,
}
This structure represents a single segment of execution. Let's understand each component:
- start_state: Contains the complete state at the beginning of the segment
- instructions: The list of WebAssembly instructions executed in this segment
- end_state: The resulting state after executing all instructions
- proof: The zero-knowledge proof for this segment's execution
The proof generation system uses these segments as building blocks. Here's how a segment is processed:
impl ExecutionSegment {
fn process_segment(&mut self) -> Result<(), Error> {
let mut current_state = self.start_state.clone();
// Execute each instruction and track state changes
for instruction in &self.instructions {
// Execute instruction
current_state = execute_instruction(current_state, instruction)?;
// Verify state transition
verify_state_transition(¤t_state)?;
// Generate constraints for the proof
self.proof.add_constraints(current_state.clone())?;
}
// Verify final state matches expected end state
if current_state != self.end_state {
return Err(Error::StateMismatch);
}
Ok(())
}
}
This implementation shows how each segment maintains execution integrity:
- It starts from the initial state
- Processes each instruction sequentially
- Verifies state transitions
- Generates proof constraints
- Ensures the final state matches expectations
Additionally, segments are grouped into bundles for efficient management:
struct BundleExecution {
segments: Vec<ExecutionSegment>,
continuation_proof: ContinuationProof,
}
Segments are grouped into bundles for efficient management:
struct BundleExecution {
segments: Vec<ExecutionSegment>,
continuation_proof: ContinuationProof,
}
impl BundleExecution {
fn new() -> Self {
BundleExecution {
segments: Vec::new(),
continuation_proof: ContinuationProof::default(),
}
}
fn add_segment(&mut self, segment: ExecutionSegment) -> Result<(), Error> {
// Verify segment connects with previous one
if let Some(last_segment) = self.segments.last() {
if last_segment.end_state != segment.start_state {
return Err(Error::SegmentMismatch);
}
}
// Process and add segment
segment.process_segment()?;
self.segments.push(segment);
Ok(())
}
fn finalize(&mut self) -> Result<(), Error> {
// Generate continuation proof
self.continuation_proof = ContinuationProof::connect_segments(&self.segments)?;
// Verify bundle consistency
self.verify_bundle_integrity()?;
Ok(())
}
}
The system ensures that segments connect properly, with the ending state of one segment matching the starting state of the next. This segmentation allows for efficient proof generation while maintaining the security and correctness of the overall system.
zkWasm generates three types of proofs that work together to verify program execution:
- Guest Circuit Proofs: Verify the correct execution of WebAssembly instructions within a segment. These proofs ensure that each instruction follows the WebAssembly specification.
- Host Circuit Proofs: Validate external function calls and their results. These proofs verify that interactions with the environment (through host functions) are correct.
- Aggregation Circuit Proofs: Combine multiple proofs into a single, verifiable proof. This includes connecting segment proofs and ensuring the overall execution is valid.
The proof generation process begins with individual segment proofs, creates continuation proofs to connect the segments, and finally combines everything into a single, verifiable proof. This hierarchical approach allows zkWasm to handle complex applications while maintaining efficient proof generation and verification.
5. Development Process and Best Practices
Developing applications for zkWasm requires careful attention to state management and performance optimization. State changes should be minimized when possible, as each state transition must be proved in the zero-knowledge system. Related operations should be batched together when possible to reduce the number of state transitions and improve proof generation efficiency.
Besides, memory management plays a crucial role in zkWasm application performance. The linear memory model of WebAssembly must be used efficiently, with careful attention paid to memory layout and access patterns. Global variables should be used judiciously, as they affect the state that must be tracked and proved.
Error handling in zkWasm applications requires special consideration due to the zero-knowledge context. Errors must be handled in a way that doesn't leak information about private data while still providing useful feedback about what went wrong. This often involves careful design of error conditions and appropriate use of public and private inputs. We will cover more about error handling in practice in the later chapters.
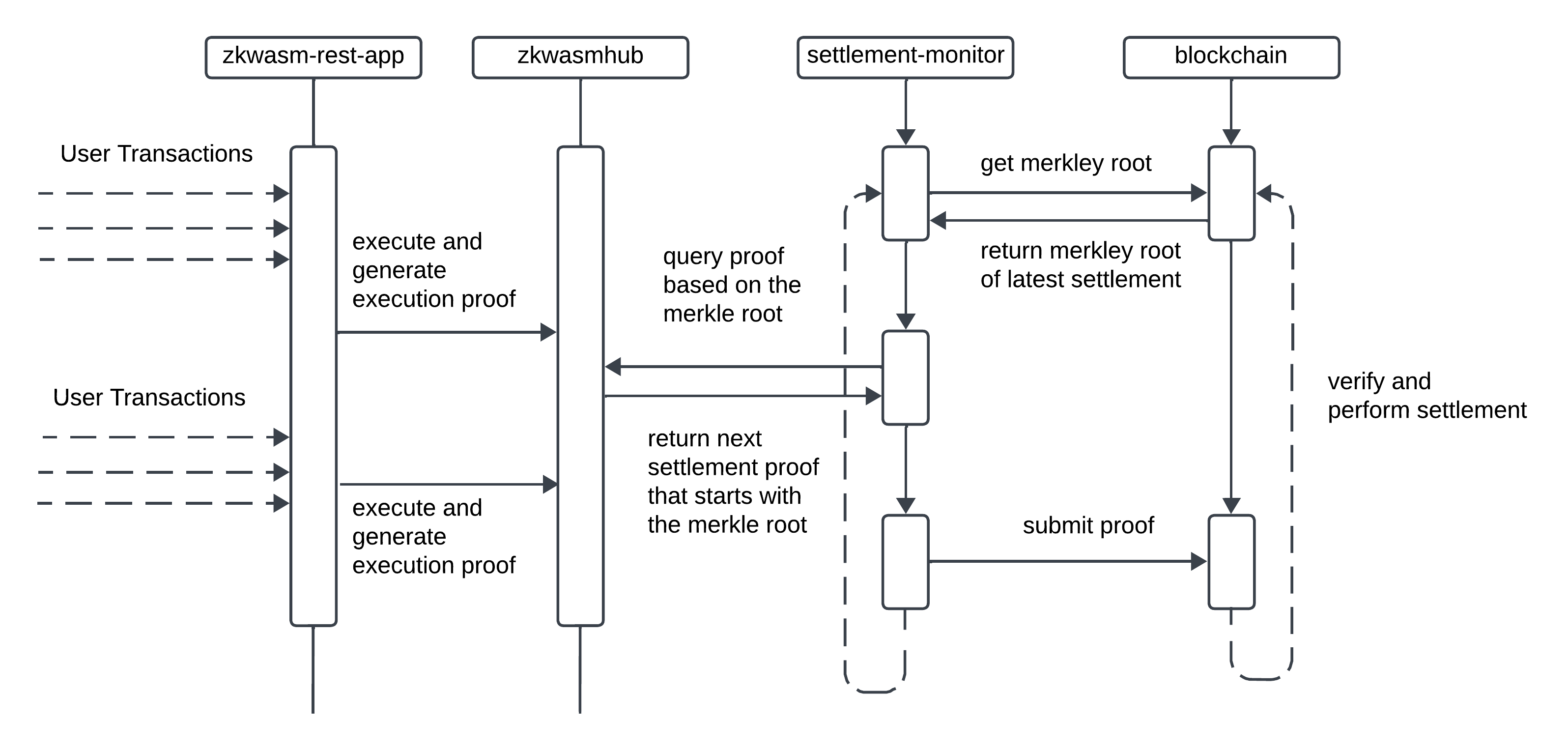
6. Architecture of a zkWasm Rollup Application